If you work in technology you will be aware that OpenAI ChatGPT has taken off like a 🚀, and the press is filled with people making rash prognostications, from gloomsters and doomsters to hypesters, and everything between.
I am particularly interested in how ChatGPT encodes (yes, I was tempted to say embodies!) a digital representation of human real-world abstractions. ChatGPT views the world primarily through the lens of text (human language) and uses machine learning to build a highly-complex mathematical model for how different parts of language are statistically related. So, while this machine learning model is huge (billions of parameters) it is much, much smaller than the corpus of text used to train it. Therefore it passes the Chaitin test — the ChatGPT neural network is a compression of the source material, and could at least potentially be exhibiting an understanding of the source material.
A useful theory is a compression of the data; comprehension is compression. You compress things into computer programs, into concise algorithmic descriptions. The simpler the theory, the better you understand something.
The Limits of Reason: Gregory Chaitin, 2006 SCIENTIFIC AMERICAN, INC.
Another perspective on human understanding comes from neuroscience, which has for many years studied how humans learn language, and create abstractions, and the role that language plays in building abstractions, particularly for abstract concepts, like “truth”, “fairness” etc. that don’t have a direct sensory manifestation.
… we use language to talk about the world, and so the information that we derive about concepts from the distributional statistics of language will include much of the information that we derive from the distributional statistics of the world. Connell points out that because we use language not only to describe the world, but also to “question, analyze, interpret, abstract, and predict it … linguistic information may capture qualitatively different aspects of conceptual information” than simulated information – aspects which may be particularly important for abstract concepts.
… Thus, for the child, language may step in and help fill the void that results from lack of experience with all those contexts. It is not surprising, then, that conceptual development proceeds apace with language development and, indeed cognitive development. Conceptual knowledge is, among other things, knowledge about the contexts in which things happen, and there are different routes to gaining that knowledge – labels, specifically, and language more generally, may be an essential stop-gap during development.
Eiling Yee (2019) Abstraction and concepts: when, how, where, what and why?, Language, Cognition and Neuroscience, 34:10, 1257-1265, DOI: 10.1080/23273798.2019.1660797
One can view ChatGPT as learning labels for concepts, and building an internal model for how concepts are grouped, differentiated and related. ChatGPT must do this without sensor input, largely via statistical analysis of languages, but also guided by humans, using reinforcement-learning with human feedback (RLHF).
To empirically test the richness and usefulness of ChatGPT’s abstractions I have created a computer program, called Finchbot, that prompts ChatGPT to create domain models using the Accord Project Concerto data modelling language. These models (if syntactically valid) can then be rendered as UML diagrams. If the initial model doesn’t meet requirements it can be iteratively refined.
Finchbot is currently based on the gpt-3.5-turbo model. Without further ado, let’s look at some sample output.
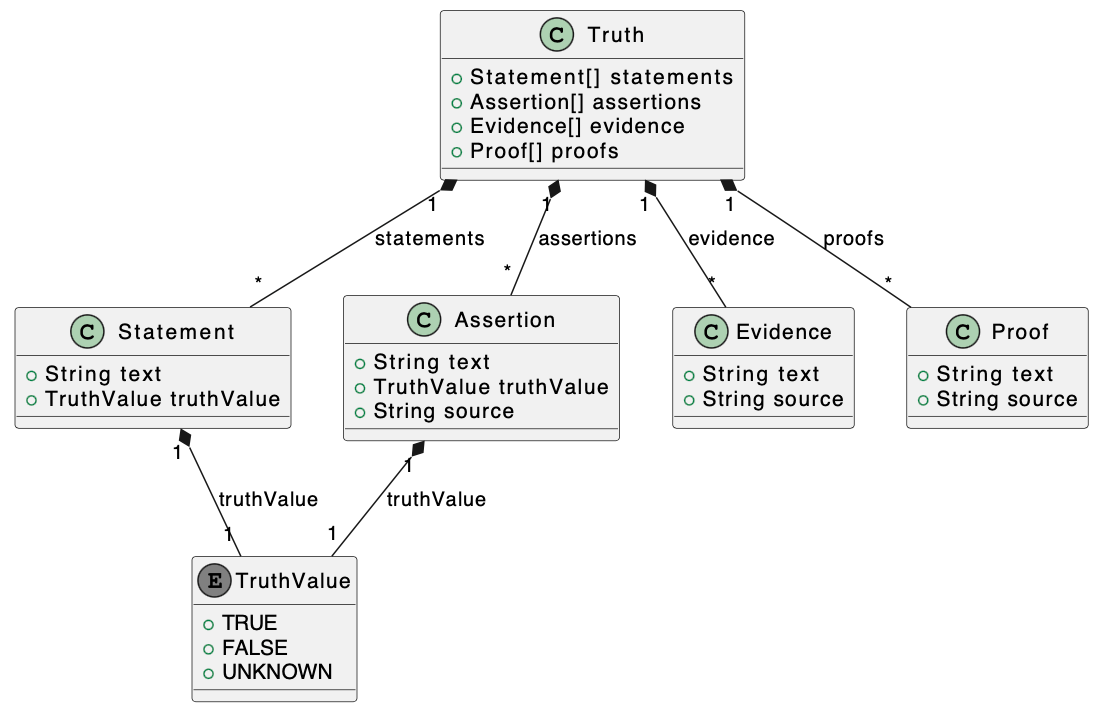
Create a model for a justice system
I find this model very impressive. ChatGPT has understood a wide variety of concepts and how they interrelate. For a “zero-shot” generation of a model it is hard to say that ChatGPT doesn’t have domain knowledge, and it has successfully built abstract concepts from the (presumably) millions of press reports of court cases and legal systems.
https://finchbot.net/?p=Create%20a%20model%20for%20a%20justice%20system.
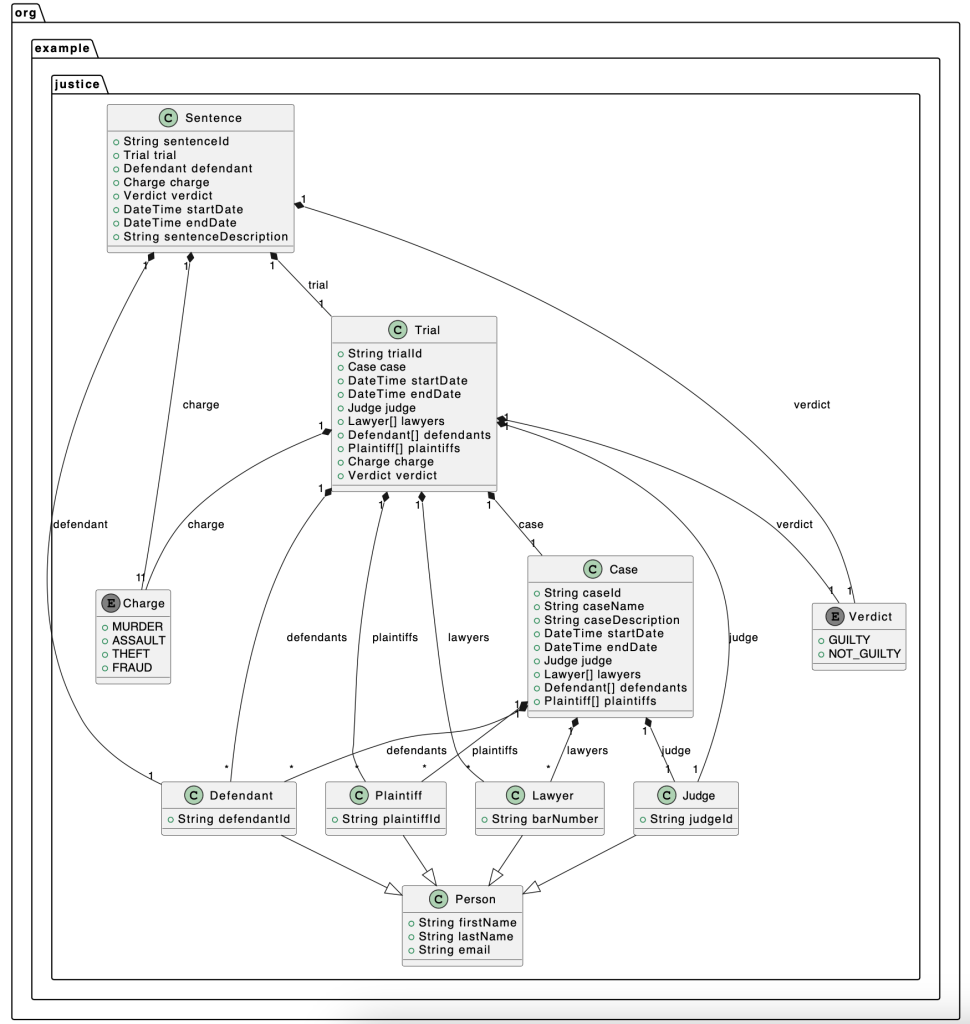
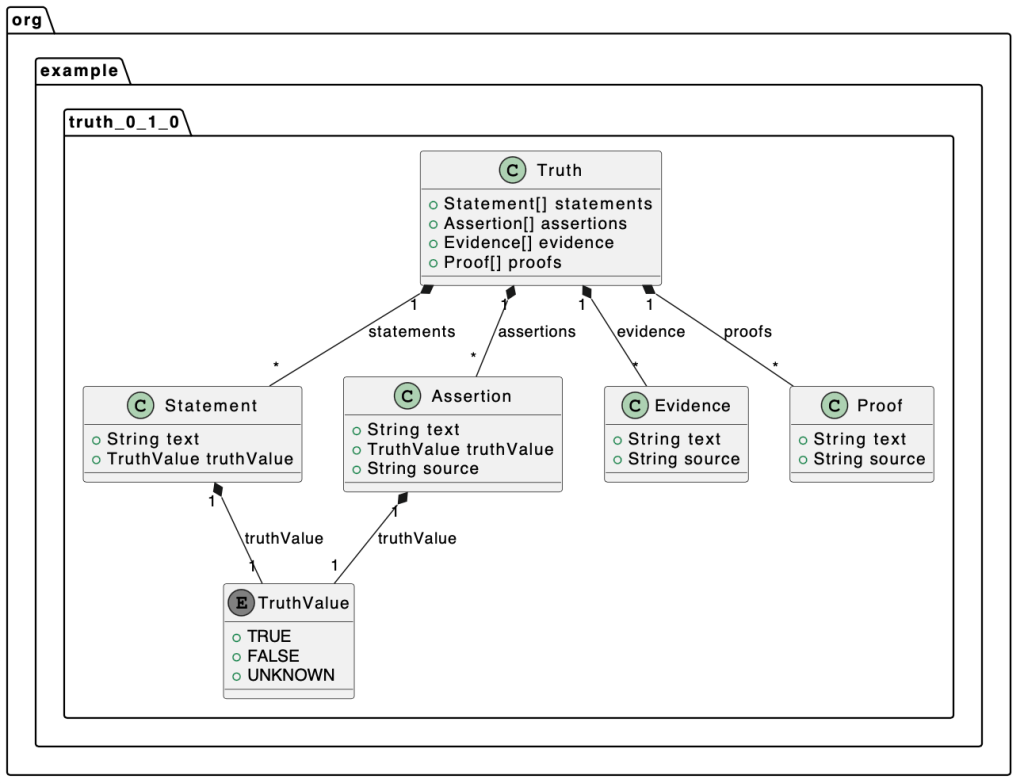
Create a model for truth
This model is more unstable and you may see significant variations on this output. I suspect this is because the prompt is so abstract, vague and open-ended, so ChatGPT has many potential paths it could go down, and it will non-deterministically return one of them. If you go much further down the path of “vague” than this, ChatGPT will start to ask you clarifying questions.
https://finchbot.net/?p=create%20a%20domain%20model%20for%20truth
Analysis, Limitations and Lessons Learned
Firstly, Finchbot creates syntactically valid models approximately 80% of the time. Occasionally it stumbles and produces invalid output:
- Creates enumeration value with spaces in their names
- Wraps enumeration values in quotes
- Inserts malformed statements (eg. uses multidimensional arrays), or gets the order of ‘extends’ and ‘identified by’ wrong. This may be an example of the limitation highlighted by Microsoft Research (see link to paper under Further Reading) for global constraints: ““global” condition could be that the first and last sentences are identical (this constraint enforces a long-range interaction between different parts of the text).”
- Gets stuck in a generation loop, repeatedly inserting the same statements
- Can struggle with some higher-level semantic Concerto consistency rules, such as all targets of relationships must be identified concepts. I think this is a manifestation of the limitation highlighted by Microsoft Research “Yet the GPT architecture does not allow for such backtracking, which means that producing this output required “far-ahead” planning.” To be able to create a relationship to a concept the concept must be identified, but ChatGPT doesn’t know whether it will need a relationship to a concept when the concept is created, and it cannot backtrack.
These errors are usually easily corrected by reminding Finchbot of the Concerto syntax. I suspect this is broadly inline with a novice human user of Concerto.
The conversational nature of the interactions with Finchbot are very natural and engaging. It is hard NOT to anthropomorphise Finchbot. You can break out of a model refinement session and ask Finchbot to tell a joke about the domain, and then resume model refinement. It is a slightly disconcerting experience!
Finchbot is a “pleaser”. The output it generates is heavily influenced by the cues you provide it via prompts. Things that are emphasised as important will figure prominently, while sometimes important concepts in the domain are omitted because they were not mentioned. This raises an issue of “you don’t know what you don’t know” for some domains; with important concepts omitted until explicitly mentioned.
Finchbot makes mistakes, both syntactic, but also conceptual. When the mistakes are pointed out, it readily admits them and corrects them.
Finchbot knows about other modelling and programming languages. It can convert the Concerto domain model to these output formats, with variable results.
Fichbot will sometimes (though not always) read data from external URLs and analyse it. I’m not sure why it only sometimes agrees to do this, perhaps simply due to randomness or load on the Open AI servers?
Finchbot can extract data models from sample text, or even create templated text that uses the data model for template variables.
When prompted to do so (or sometimes, even unprompted) Finchbot will return computational functions over the data model. Finchbot currently includes code that strips these functions out of the data model definition, but there’s clearly more that could be done here…
Finchbot is sensitive to the underlying ChatGPT tuning parameters: temperature, top_p, frequency_penalty, presence_penalty. Tuning these is largely a process of trial-and-error, and good results can sometimes degrade, without any Finchbot changes.
Performance is very variable, with response times anywhere from hundreds of milliseconds to dozens of seconds, due to the load on the ChatGPT service. Sometimes responses will timeout.
Small changes to the initial ChatGPT prompt can make big differences to the output — often in surprising ways. Creating an initial prompt that works reliably is a laborious process.
Summary
In summary, I think Finchbot is operating at the level of a novice user of Concerto, and a novice business analyst / data modeller, but FOR ALL THE WORLD’S DATA. This is incredibly impressive, and exciting.
Does Finchbot understand? I will leave that for you (and John Searle, see link below) to decide, but a wise man once said “When it doesn’t work, it’s Artificial Intelligence, when it works, it’s just Software Engineering…”
Give it a try yourself!
Further Reading
A great introduction to language processing using neural networks.
Combining large language model with symbolic reasoning.
Abstraction and concepts: when, how, where, what and why? by Eiling Yee
https://doi.org/10.1080/23273798.2019.1660797
The Limits of Reason by Gregory Chaitin
https://web.archive.org/web/20160304192140/https://www.cs.auckland.ac.nz/~chaitin/sciamer3.pdf
John Searle – The Chinese Room Argument
https://plato.stanford.edu/entries/chinese-room/

April 1, 2023 at 8:56 am
Hi Dan. Thanks for the article very interesting and some good links there.
What type of training was needed on the syntax of the Concerto model?
I’ve seen other systems that train language models on code, but what sheets seems odd to me is that we train them on the ‘human text’. I was expecting the grammar or the AST to appear somewhere
All the best Matthew
LikeLike