
Foundational LLMs are trained on huge corpuses of text collected from the public Internet, including websites, books, Wikipedia, GitHub, academic papers, chat logs, Enron emails (!) etc. One of the better known public collections of training data is called The Pile and is an 800 GB dataset of diverse text for language modelling.
In this article I will examine how the training sets for LLMs should influence your choice of data formats and best-practices for data formats that can be generated by LLMs.
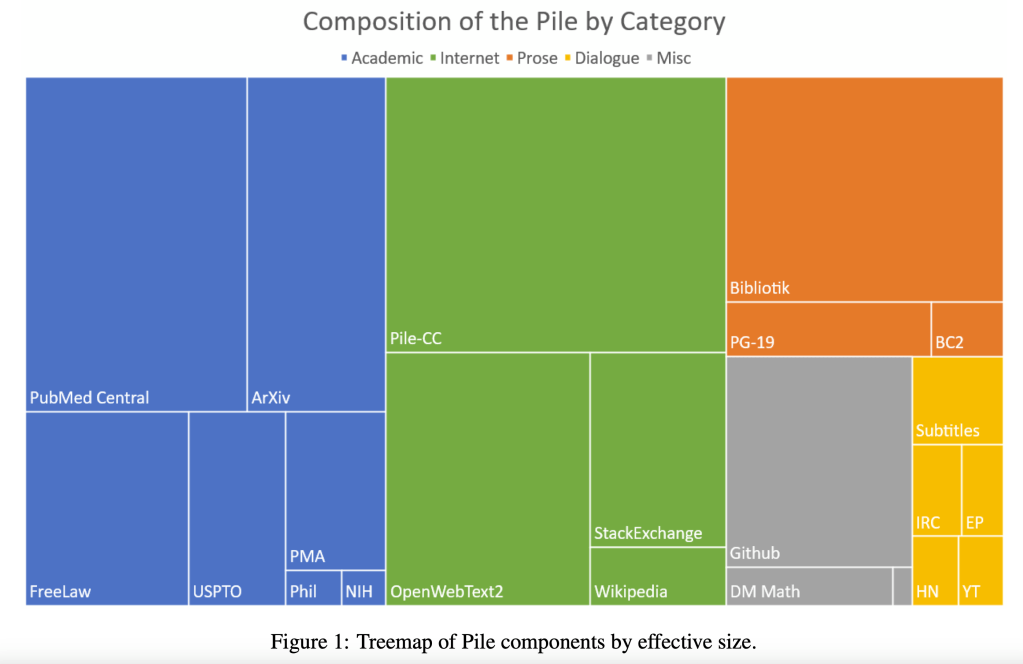
You can read more about the composition of The Pile in the associated research paper.
Armed with some knowledge of how foundational LLMs are trained, it should be self-evident that if you want LLMs to generate programs, or data in a data format, the data format should appear repeatedly within its training set. Practically speaking this means that many sample documents should be available on the public web, GitHub, StackOverflow etc. This rules out most “home grown” or proprietary data formats. LLMs will in essence prove to be a forcing function towards adoption of well-documented public data formats; including Open Source data formats.
In this exchange I ask ChatGPT to compare Accord Project Concerto with the wholly fictional DocuSign Data Model Definition Language (DMDL). ChatGPT blithely hallucinates a plausible example DMDL model!

ChatGPT then gives the game away by also hallucinating the URL to the documentation page for the format which, of course, does not exist…

In contrast when ChatGPT is asked for a link to the Accord Project Concerto documentation it is valid (and has been for many years), so ChatGPT has knowledge of Concerto in its training set.
However, not all data formats are created equal, and some are much easier for a “next token predicting machine” to produce than others. For example, when ChatGPT is asked to compare Accord Project Concerto with XML Schema it produces this plausible answer:

This has been born out by my own testing, which has shown that ChatGPT struggles to maintain long-range context, or apply complex semantic or syntactic rules to its output. In essence, if some part of the output requires long-range referential integrity with another part of the output, or if the presence of multiple tokens should imply the presence of other tokens, ChatGPT starts to struggle. My intuition is that these are many of the same limitations that humans struggle with: verbose data formats with lots of long-range referential integrity are very hard for humans to work with inside a basic text editor as well!
In summary, here are some best-practices for choosing LLM friendly data formats:
- If an open format exists in the LLM training set, use that, if possible. For the latest models this is currently data that was on the public Internet around mid-2021.
- The simpler the format, the more accurate LLM generation is likely to be. However, this must be weighed against the prevalence of samples of the format in (1).
- Verbose formats (for example, XML Schema) will take much longer to generate, and hit token limits faster, than more concise formats.
- Provide “few-shot” prompt-engineered examples of the data format if the training set is small. Beware however that you may quickly hit token limits, or confuse the LLM by over-constraining the output.
- LLM generation struggles with long-range referential integrity constraints, for example in Accord Project Concerto you can only have a relationship (foreign-key) to a concept that has an identifying field. Text generation is typically performed in a single-pass, so data formats that require contextual modification of prior output will be much harder to work with. It might be interesting to first ask the LLM to identify identifiable concepts before generating the appropriate text.
In short, LLMs will perform well at generating structured text that humans could easily produce in a basic text editor. They will struggle to produce verbose, deeply nested output, containing complex referential integrity constraints, or finicky formatting. Yes, all those DevOps deployment Yaml files I am looking at you! 😊

Leave a comment